
IS026262의 Part5. 중 메모리에 대한 요구사항이 있다. 메모리 테스트에 대한 내용이 필요하여 아래 포스팅을 번역함.
https://barrgroup.com/Embedded-Systems/How-To/Memory-Test-Suite-C
재사용이 가능한 임베디드 소프트웨어가 있다면 메모리 테스트입니다. 이 포스팅에서는 세 가지 효율적이고 적용 가능한 메모리 테스트 기능 셋을 사용하여 가장 일반적인 메모리 문제를 테스트하는 방법을 보여줍니다.
거의 모든 임베디드 개발자는 자신의 경력 중 어느 시점에 도달하였을때 메모리 테스트를 작성하여야 합니다. 종종 프로토타입 하드웨어가 준비되면 보드 설계자는 주소 및 데이터 라인을 올바르게 연결하고 다양한 메모리 칩이 올바르게 작동하는지 확인하기를 원합니다. 그렇지 않은 경우에도 최소한 시스템이 리셋 될 때까지 온보드 RAM을 테스트하는 것이 바람직합니다. 임베디드 소프트웨어 개발자는 무엇이 잘못 될지 파악하고 잠재적인 문제를 발견 할 수있는 일련의 테스트를 설계해야합니다.
언뜻보기에 메모리 테스트를 작성하는 것은 상당히 간단한 시도처럼 보일 수 있습니다. 그러나 문제를 좀 더 면밀히 살펴보면 간단한 테스트로 미묘한 메모리 문제를 감지하는 것이 어려울 수 있음을 알 수 있습니다. 사실, 프로그래머인 naïveté의 결과로 많은 임베디드 시스템은 가장 치명적인 메모리 오류만 감지하는 메모리 테스트를 포함합니다. 믿을수 없겠지만, 이들 중 일부는 메모리 칩이 보드에서 제거되었음을 알지 못할 수도 있습니다!
메모리 테스트의 목적은 메모리 장치의 각 저장 위치가 작동하는지 확인하는 것입니다. 즉, 특정 주소에 값 50을 저장하면 동일한 값에 다른 값이 기록 될 때까지 해당 값을 찾을 수 있습니다. 모든 메모리 테스트의 기본 아이디어는 메모리 장치의 각 주소에 일부 데이터 집합을 쓰고 데이터를 다시 읽음으로써 데이터를 확인하는 것입니다. 다시 읽은 모든 값이 쓰여진 값과 같으면 메모리 장치는 테스트를 통과했다고 말합니다. 보시다시피, 합격 결과가 의미가 있음을 확신 할 수있는 일련의 데이터 값을 신중하게 선택해야합니다.
물론 방금 설명한 것과 같은 메모리 테스트는 파괴적일 수 밖에 없습니다. 메모리를 테스트하는 과정에서 이전 내용을 덮어 써야합니다. 일반적으로 비 휘발성 메모리의 내용을 덮어 쓰는 것은 비현실적이므로이 기사에서 설명하는 테스트는 일반적으로 RAM 테스트에만 사용됩니다. 그러나 플래시와 같은 비 휘발성 메모리 장치의 내용이 제품 개발 단계 에서처럼 중요하지 않은 경우에도 동일한 알고리즘을 사용하여 해당 장치를 테스트 할 수 있습니다.
공통 메모리 문제
가능한 테스트 알고리즘을 구현하기 전에 발생할 수있는 메모리 문제 유형에 대해 잘 알고 있어야합니다. 소프트웨어 엔지니어들 사이에서 가장 흔한 오해 중 하나는 대부분의 메모리 문제가 칩 자체에서 발생한다는 것입니다. 한 때는(몇 십 년 전) 중요한 문제 였지만 이 유형의 문제는 점차 희소합니다. 요즈음, 메모리 장치 제조업체는 칩 배치마다 다양한 후반 작업 테스트를 수행합니다. 특정 배치에 문제가 있으면 나쁜 칩 중 하나가 시스템에 침투 할 가능성이 극도로 희박합니다.
발생할 수있는 메모리 칩 문제 중 하나는 치명적인 오류입니다. 이것은 일반적으로 제조 후 칩에 물리적 또는 전기적 손상의 일종으로 인해 발생합니다. 치명적인 오류는 일반적이지 않으며 일반적으로 칩의 많은 부분에 영향을 미칩니다. 큰 영역이 영향을 받기 때문에 치명적인 오류가 적절한 테스트 알고리즘에 의해 감지된다고 가정하는 것이 합리적입니다.
내 경험상, 실제 메모리 문제의 가장 일반적인 원인은 회로 기판입니다. 일반적인 회로 보드 문제는 프로세서와 메모리 장치 간의 배선, 메모리 칩 누락 및 잘못 삽입 된 메모리 칩 문제입니다. 이것들은 좋은 메모리 테스트 알고리즘이 탐지 할 수 있어야하는 문제점들이다. 그러한 테스트는 특별히 그들을 찾지 않고 치명적인 메모리 실패를 탐지 할 수 있어야합니다. 이제 회로 보드 문제에 대해 자세히 설명합시다.
전기 배선 문제
전기 배선 문제는 보드의 설계 또는 생산상의 오류 또는 제조 후 발생한 손상의 결과로 발생할 수 있습니다. 메모리 장치를 프로세서에 연결하는 각 와이어는 주소 라인, 데이터 라인 또는 제어 라인의 세 가지 유형 중 하나입니다. 주소 및 데이터 라인은 메모리 위치를 선택하고 데이터를 각각 전송하는 데 사용됩니다. 제어 라인은 프로세서가 위치를 읽거나 쓰고 싶어하는지 그리고 데이터가 언제 전송되는지를 메모리 장치에 알려줍니다. 불행하게도 하나 이상의 와이어가 단락(예 : 보드의 다른 와이어에 연결)되거나 단선(다른 것과 연결되지 않음) 등의 방식으로 부적절하게 연결되거나 손상 될 수 있습니다. 이러한 문제는 종종 납땜이 번지거나 또는 패턴이 끊어지는 일부에 의해 발생합니다. 두 경우 모두 그림 1에 나와 있습니다.
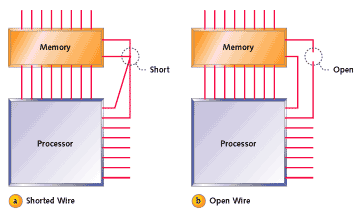
그림 1. 배선 문제
프로세서에 대한 전기 연결 문제로 인해 메모리 장치가 올바르게 작동하지 않게됩니다. 데이터가 잘못 저장되거나, 잘못된 주소에 저장되거나, 전혀 저장되지 않을 수 있습니다. 이러한 증상은 각각 데이터, 주소 및 제어 라인의 배선 문제로 설명 할 수 있습니다.
데이터 라인에 문제가 있는 경우 여러 데이터 비트가 “stuck togeter”것처럼 보일 수 있습니다 (예 : 전송 된 데이터에 관계없이 둘 이상의 비트가 항상 같은 값을 포함). 비슷하게, 데이터 비트는 “Stuck-at high”(항상 1) 또는 “Stuck-at low”(항상 0) 일 수 있습니다. 이러한 문제는 각 데이터 핀을 다른 모든 것과 독립적으로 0과 1로 설정할 수 있는지 테스트하도록 설계된 일련의 데이터 값을 작성하여 감지 할 수 있습니다.
주소 표시 줄에 배선 문제가 있는 경우 두 메모리 위치의 내용이 겹치는 것처럼 보일 수 있습니다. 즉, 한 주소에 기록 된 데이터는 실제로 다른 주소의 내용을 덮어 씁니다. 이것은 쇼트 또는 오픈 된 어드레스 비트가 메모리 장치로 하여금 프로세서에 의해 선택된 어드레스와 다른 어드레스를 보게하기 때문에 발생합니다.
또 다른 가능성은 제어 선 중 하나가 단락되거나 개방된다는 것입니다. 이론적으로 제어 라인 문제에 대한 특정 테스트를 개발하는 것이 가능하지만, 일반적인 테스트를 설명하는 것은 불가능합니다. 많은 제어 신호의 동작은 프로세서 또는 메모리 아키텍처에 따라 다릅니다. 다행히도 제어 라인에 문제가 있으면 메모리가 전혀 작동하지 않으며 다른 메모리 테스트에 의해 감지됩니다. 컨트롤 라인에 문제가 있다고 생각되면 특정 테스트를 수행하기 전에 디자이너의 조언을 구하는 것이 가장 좋습니다.
누락 된 메모리 칩
누락 된 메모리 칩은 분명히 발견되어야하는 문제입니다. 불행하게도, 연결되지 않은 전선의 용량 성(전압을 부여했을 때 그대로 전기적인 전압을 일시적으로 유지하는 것. 접지 되지 않았기 때문)으로 인해 일부 메모리 테스트는이 문제를 감지하지 못합니다. 예를 들어, 다음 테스트 알고리즘을 사용하기로 결정했다고 가정하십시오. 메모리의 첫 번째 위치에 값 1을 쓰고, 값을 다시 읽음으로써 값을 확인하고, 두 번째 위치에 2를 쓰고, 값을 확인하고, 세 번째 위치에 3을 쓰고, 확인하는등, 각각의 판독은 대응하는 기입 직후에 발생하기 때문에, 판독 된 데이터는 이전의 기입으로 부터의 데이터 버스 상에 남아있는 전압 이상을 나타낼 수 없다. 데이터를 너무 빨리 다시 읽으면 버스의 다른 끝에 메모리 칩이 없더라도 데이터가 메모리에 올바르게 저장되었다고 표시됩니다!
누락 된 메모리 칩을 감지하려면 테스트를 변경해야합니다. 대응하는 기록 직후에 검증 판독을 수행하는 대신에, 수 개의 연속 기록을 수행 한 다음 동일한 갯수를 연속으로 읽어오는 것이 바람직합니다. 예를 들어 값 1을 첫 번째 위치에, 2를 두 번째 위치에, 3을 세 번째 위치에 기록한 다음 첫 번째 위치, 두 번째 위치 등에서 데이터를 확인하십시오. 데이터 값이 고유 한 경우, 누락 된 칩이 감지됩니다. 첫 번째 값은 처음 값 (1)이 아닌 마지막 값 (3)에 해당합니다.
부적절하게 삽입 된 칩
메모리 칩이 있지만 소켓에 잘못 삽입 된 경우, 시스템은 일반적으로 배선 문제 또는 누락 된 칩이있는 것처럼 동작합니다. 즉, 메모리 칩의 일부 핀은 소켓에 전혀 연결되지 않거나 잘못된 위치에 연결됩니다. 이 핀은 데이터 버스, 주소 버스 또는 제어 배선의 일부가됩니다. 따라서 배선 문제와 칩 누락 여부를 테스트하는 동안 부적절하게 삽입 된 칩은 자동으로 감지됩니다.
메모리 테스트 전략
계속하기 전에 우리가 탐지 할 수 있어야 하는 메모리 문제 유형을 빠르게 검토합니다. 메모리 칩은 내부 오류가 있는 경우는 드물지만, 실제로 발생하면 치명적일 수 있으며 모든 테스트에 의해 감지됩니다. 일반적인 문제의 근원은 배선 문제가 발생할 수 있거나 메모리 칩이 누락되거나 부적절하게 삽입 될 수있는 회로 기판입니다. 다른 메모리 문제가 발생할 수 있지만 여기에 설명 된 문제가 가장 일반적입니다.
테스트 데이터와 주소 테스트 순서를 주의 깊게 선택하면 위에서 설명한 모든 메모리 문제를 감지 할 수 있습니다. 일반적으로 메모리 테스트를 작고 단순한 부분으로 나누는 것이 가장 좋습니다. 이렇게 하면 전체 테스트의 효율성과 코드의 가독성을 향상시킬 수 있습니다. 보다 구체적인 테스트를 통해 문제가 발생한 경우 문제의 원인에 대한 자세한 정보를 제공 할 수도 있습니다.
데이터 버스 테스트, 주소 버스 테스트 및 장치 테스트라는 세 가지 개별 메모리 테스트를 하는 것이 가장 좋습니다. 앞의 두 가지 테스트는 전기 배선 문제를 및 부적절하게 칩을 삽입하는 문제을 탐지하는 반면 세 번째 테스트는 누락 된 칩 문제와 치명적인 오류를 감지하기 위한 것입니다. 의도하지는 않은 결과지만, 장치 테스트는 제어 버스의 문제점을 밝혀 낼 것이지만, 그러한 문제의 근원에 대한 유용한 정보는 제공하지 않을 것이다.
이 세 가지 검사를 실행하는 순서가 중요합니다. 적절한 순서는 데이터 버스 테스트, 주소 버스 테스트, 장치 테스트 순입니다. 이는 주소 버스 테스트가 작동중인 데이터 버스를 가정하고, 주소 버스와 데이터 버스가 모두 양호한 것으로 알려지지 않는 한 장치 테스트 결과가 의미가 없기 때문입니다. 테스트 중 하나라도 실패하면 보드 설계자와 협력하여 문제의 원인을 찾아야 합니다. 테스트가 실패한 데이터 값 또는 주소를 살펴봄으로써 회로 기판에서 문제를 신속하게 격리 할 수 있어야 합니다.
데이터 버스 테스트
우리가 테스트하고자하는 첫 번째 일은 데이터 버스 배선입니다. 프로세서가 데이터 버스에 입력 한 값이 다른 쪽 끝의 메모리 장치에서 올바르게 수신되는지 확인해야합니다. 테스트 할 수있는 가장 확실한 방법은 가능한 모든 데이터 값을 쓰고 메모리 장치가 각 데이터를 성공적으로 저장하는지 확인하는 것입니다. 그러나 이것이 가능한 가장 효율적인 테스트는 아닙니다. 더 빠른 방법은 한 번에 한 비트 씩 버스를 테스트하는 것입니다. 데이터 버스는 각 데이터 비트가 다른 데이터 비트와 독립적으로 0 및 1로 설정 될 수 있는지 테스트를 통과합니다.
|
00000001
|
|
00000010
|
|
00000100
|
|
00001000
|
|
00010000
|
|
00100000
|
|
01000000
|
|
10000000
|
표 1. “워킹 1의 테스트”에 대한 연속적인 데이터 값
독립적으로 각 비트를 테스트하는 좋은 방법은 소위 “워킹 1의 테스트”를 수행하는 것입니다. 표 1은 이 테스트의 8 비트 버전에서 사용 된 데이터 패턴을 보여줍니다. 이 테스트의 이름은 단일 데이터 비트가 1로 설정되고 전체 데이터 단어를 통해 “걷는”사실로 부터 옵니다. 테스트 할 데이터 값의 수는 데이터 버스의 너비와 같습니다. 이렇게 하면 테스트 패턴 수가 2n에서 n으로 줄어 듭니다. 여기서 n은 데이터 버스의 너비입니다.
이 시점에서 데이터 버스 만 테스트하기 때문에 모든 데이터 값을 동일한 주소에 쓸 수 있습니다. 메모리 장치 내의 모든 주소가 수행합니다. 그러나 데이터 버스가 둘 이상의 메모리 칩으로 갈 때 분할되면 각 칩 내 하나씩 여러 주소에서 데이터 버스 테스트를 수행해야합니다.
워킹 1의 테스트를 수행하려면 테이블에 첫 번째 데이터 값을 쓰고 다시 읽은 다음 두 번째 값을 쓰고 확인하는 등의 방법으로 확인하십시오. 테이블 끝에 도달하면 테스트가 완료됩니다. 이번에는 해당 칩을 찾지 않아도됩니다. 사실 이 테스트는 메모리 칩이 설치되지 않은 경우에도 의미있는 결과를 제공합니다.
typedef unsigned char datum; /* Set the data bus width to 8 bits. */
/**********************************************************************
*
* Function: memTestDataBus()
*
* Description: Test the data bus wiring in a memory region by
* performing a walking 1's test at a fixed address
* within that region. The address (and hence the
* memory region) is selected by the caller.
*
* Notes:
*
* Returns: 0 if the test succeeds.
* A non-zero result is the first pattern that failed.
*
**********************************************************************/
datum
memTestDataBus(volatile datum * address)
{
datum pattern;
/*
* Perform a walking 1's test at the given address.
*/
for (pattern = 1; pattern != 0; pattern <<= 1)
{
/*
* Write the test pattern.
*/
*address = pattern;
/*
* Read it back (immediately is okay for this test).
*/
if (*address != pattern)
{
return (pattern);
}
}
return (0);
} /* memTestDataBus() */
Listing 1. 데이터 버스 테스트
Listing 1의 memTestDataBus () 함수는 C에서 walking 1의 테스트를 구현하는 방법을 보여줍니다. 호출자가 테스트 주소를 선택하고 해당 주소에서 전체 데이터 값 세트를 테스트 한다고 가정합니다. 데이터 버스가 제대로 작동하면 함수는 0을 반환하고 그렇지 않으면 테스트에 실패한 데이터 값을 반환합니다. 반환 값에 설정된 비트는 첫 번째 오류 데이터 행이있는 경우 해당 행에 해당합니다.
주소 버스 테스트
데이터 버스가 제대로 작동하는지 확인한 후 다음에 주소 버스를 테스트해야합니다. 주소 버스 문제로 인해 메모리 위치가 겹치는 것을 기억하십시오. 가능한 많은 주소가 중복 될 수 있습니다. 그러나 모든 가능한 조합을 확인할 필요는 없습니다. 위의 데이터 버스 테스트의 예를 따르고 테스트하는 동안 각 주소 비트를 격리해야합니다. 각 주소 핀을 다른 주소에 영향을주지 않고 0과 1로 설정할 수 있는지 확인하면됩니다.
모든 가능한 조합을 포함 할 수있는 가장 작은 주소 집합은 “2의 제곱 (power-of-two)”주소 집합입니다. 이 주소는 걷기 1의 테스트에 사용 된 데이터 값 세트와 유사합니다. 해당 메모리 위치는 0001h, 0002h, 0004h, 0008h, 0010h, 0020h 등입니다. 또한 주소 0000h도 테스트해야합니다. 위치가 겹칠 가능성이 있기 때문에 주소 버스 테스트를 구현하기가 더 어려워집니다. 주소 중 하나에 기록한 후 다른 주소가 겹쳐 쓰여져 있지 않은지 확인해야 합니다.
이 방법으로 모든 주소 라인을 테스트 할 수있는 것은 아닙니다. 주소의 일부 – 가장 왼쪽 비트 -는 메모리 칩 자체를 선택합니다. 데이터 버스 폭이 8 비트보다 크면 다른 부분, 즉 가장 오른쪽 비트가 중요하지 않을 수 있습니다. 이러한 추가 비트는 테스트를 통해 일정하게 유지되며 테스트 주소의 수를 줄입니다. 예를 들어 프로세서에 32 개의 주소 비트가 있으면 최대 4GB의 메모리를 주소 지정할 수 있습니다. 128K 메모리 블록을 테스트하려면 15 개의 최상위 주소 비트가 일정하게 유지됩니다. 이 경우, 주소 버스의 가장 오른쪽 17 비트(=128k) 만 실제로 테스트 할 수 있습니다. (128K는 총 4GB 주소 공간의 1 / 32,768 번째입니다.)
두 개의 메모리 위치가 겹치지 않았음을 확인하려면 먼저 디바이스 내의 2의 거듭 제곱 오프셋에 초기 데이터 값을 써야합니다. 그런 다음 새로운 값 (초기 값의 반전 된 복사본)을 첫 번째 테스트 오프셋에 쓰고 다른 모든 오프셋에서 초기 데이터 값이 저장되는지 확인합니다. 방금 작성한 위치가 아닌 다른 위치에서 새 데이터 값을 찾으면 현재 주소 비트에 문제가 있음을 발견했습니다. 겹침이 없으면 나머지 각 오프셋에 대해 절차를 반복하십시오.
/**********************************************************************
*
* Function: memTestAddressBus()
*
* Description: Test the address bus wiring in a memory region by
* performing a walking 1's test on the relevant bits
* of the address and checking for aliasing. This test
* will find single-bit address failures such as stuck
* -high, stuck-low, and shorted pins. The base address
* and size of the region are selected by the caller.
*
* Notes: For best results, the selected base address should
* have enough LSB 0's to guarantee single address bit
* changes. For example, to test a 64-Kbyte region,
* select a base address on a 64-Kbyte boundary. Also,
* select the region size as a power-of-two--if at all
* possible.
*
* Returns: NULL if the test succeeds.
* A non-zero result is the first address at which an
* aliasing problem was uncovered. By examining the
* contents of memory, it may be possible to gather
* additional information about the problem.
*
**********************************************************************/
datum *
memTestAddressBus(volatile datum * baseAddress, unsigned long nBytes)
{
unsigned long addressMask = (nBytes/sizeof(datum) - 1);
unsigned long offset;
unsigned long testOffset;
datum pattern = (datum) 0xAAAAAAAA;
datum antipattern = (datum) 0x55555555;
/*
* Write the default pattern at each of the power-of-two offsets.
*/
for (offset = 1; (offset & addressMask) != 0; offset <<= 1)
{
baseAddress[offset] = pattern;
}
/*
* Check for address bits stuck high.
*/
testOffset = 0;
baseAddress[testOffset] = antipattern;
for (offset = 1; (offset & addressMask) != 0; offset <<= 1)
{
if (baseAddress[offset] != pattern)
{
return ((datum *) &baseAddress[offset]);
}
}
baseAddress[testOffset] = pattern;
/*
* Check for address bits stuck low or shorted.
*/
for (testOffset = 1; (testOffset & addressMask) != 0; testOffset <<= 1)
{
baseAddress[testOffset] = antipattern;
if (baseAddress[0] != pattern)
{
return ((datum *) &baseAddress[testOffset]);
}
for (offset = 1; (offset & addressMask) != 0; offset <<= 1)
{
if ((baseAddress[offset] != pattern) && (offset != testOffset))
{
return ((datum *) &baseAddress[testOffset]);
}
}
baseAddress[testOffset] = pattern;
}
return (NULL);
} /* memTestAddressBus() */
Listing 2. 주소 버스 테스트
Listing 2의 memTestAddressBus () 함수는 이것을 어떻게 실제로 수행 할 수 있는지 보여준다. 함수는 두 개의 매개 변수를받습니다. 첫 번째 매개 변수는 테스트 할 메모리 블록의 기본 주소이고 두 번째 매개 변수는 크기 (바이트)입니다. 크기는 테스트 할 주소 비트를 결정하는 데 사용됩니다. 최상의 결과를 얻으려면 기본 주소는 각 비트에 0을 포함하고 있어야 합니다. 주소 버스 테스트가 실패하면 첫 번째 오류가 감지 된 주소가 반환됩니다. 그렇지 않으면 이 함수는 성공을 나타 내기 위해 NULL을 반환합니다.
장치 테스트
주소 및 데이터 버스 배선이 작동 중임을 알게되면 메모리 장치 자체의 무결성을 테스트해야 합니다. 테스트 할 것은 디바이스의 모든 비트가 0과 1을 모두 유지할 수 있다는 것입니다. 이것은 구현하기에 상당히 간단한 테스트이지만 이전 두 개보다 실행 시간이 훨씬 오래 걸립니다.
완벽한 장치 테스트를 위해서는 모든 메모리 위치를 두 번 방문 (쓰기 및 확인)해야합니다. 두 번째 패스에서 해당 값을 반전하기 전 까지는 자유롭게 첫 번째 패스의 데이터 값을 선택할 수 있습니다. 그리고 메모리 칩이 누락 될 가능성이 있기 때문에 주소가 바뀌는 (그러나 같지는 않은) 데이터 세트를 선택하는 것이 가장 좋습니다. 간단한 예제는 “증분 테스트”입니다.
|
Offset
|
Value
|
Inverted Value
|
|
00h
|
00000001
|
11111110
|
|
01h
|
00000010
|
11111101
|
|
02h
|
00000011
|
11111100
|
|
03h
|
00000100
|
11111011
|
|
…
|
…
|
…
|
|
FEh
|
11111111
|
00000000
|
|
FFh
|
00000000
|
11111111
|
표 2. 증가 테스트의 데이터 값
증분 테스트의 오프셋 및 해당 데이터 값은 표 2의 첫 번째 두 번째 열에 표시됩니다. 세 번째 열은이 테스트의 두 번째 단계에서 사용 된 반전 된 데이터 값을 보여줍니다. 마지막 열은 감소 테스트를 나타냅니다. 가능한 다른 많은 데이터 선택이 있지만 증가하는 데이터 패턴은 적절하고 계산하기 쉽습니다.
/**********************************************************************
*
* Function: memTestDevice()
*
* Description: Test the integrity of a physical memory device by
* performing an increment/decrement test over the
* entire region. In the process every storage bit
* in the device is tested as a zero and a one. The
* base address and the size of the region are
* selected by the caller.
*
* Notes:
*
* Returns: NULL if the test succeeds.
*
* A non-zero result is the first address at which an
* incorrect value was read back. By examining the
* contents of memory, it may be possible to gather
* additional information about the problem.
*
**********************************************************************/
datum *
memTestDevice(volatile datum * baseAddress, unsigned long nBytes)
{
unsigned long offset;
unsigned long nWords = nBytes / sizeof(datum);
datum pattern;
datum antipattern;
/*
* Fill memory with a known pattern.
*/
for (pattern = 1, offset = 0; offset < nWords; pattern++, offset++)
{
baseAddress[offset] = pattern;
}
/*
* Check each location and invert it for the second pass.
*/
for (pattern = 1, offset = 0; offset < nWords; pattern++, offset++)
{
if (baseAddress[offset] != pattern)
{
return ((datum *) &baseAddress[offset]);
}
antipattern = ~pattern;
baseAddress[offset] = antipattern;
}
/*
* Check each location for the inverted pattern and zero it.
*/
for (pattern = 1, offset = 0; offset < nWords; pattern++, offset++)
{
antipattern = ~pattern;
if (baseAddress[offset] != antipattern)
{
return ((datum *) &baseAddress[offset]);
}
}
return (NULL);
} /* memTestDevice() */
Listing 3. 디바이스 테스트
Listing 3의 memTestDevice () 함수는 이러한 2 회 증가 / 감소 테스트를 구현한다. 호출자로부터 두 개의 매개 변수를받습니다. 첫 번째 매개 변수는 시작 주소이고 두 번째 매개 변수는 테스트 할 바이트 수입니다. 이 매개 변수를 사용하면 덮어 쓸 메모리 영역을 최대한 제어 할 수 있습니다. 이 함수는 성공시 NULL을 반환합니다. 그렇지 않으면 잘못된 데이터 값을 포함하는 첫 번째 주소가 반환됩니다.
전부 모아보면..
토론을 보다 구체적으로 하기 위해 실제적인 예를 생각해 봅시다. 주소 00000000h에 SRAM의 64K chunk를 테스트 한다고 가정합니다. 이를 위해 Listing 3과 같이 세 가지 테스트 루틴을 적절한 순서로 호출한다. 각각의 경우 첫 번째 매개 변수는 메모리 블록의 기본 주소이다. 데이터 버스의 너비가 8 비트보다 큰 경우 몇 가지 수정이 필요합니다.
int
memTest(void)
{
#define BASE_ADDRESS (volatile datum *) 0x00000000
#define NUM_BYTES (64 * 1024)
if ((memTestDataBus(BASE_ADDRESS) != 0) ||
(memTestAddressBus(BASE_ADDRESS, NUM_BYTES) != NULL) ||
(memTestDevice(BASE_ADDRESS, NUM_BYTES) != NULL))
{
return (-1);
}
else
{
return (0);
}
} /* memTest() */
Listing 4. 메모리 테스트 엔진
개별 메모리 테스트 루틴 중 하나가 0이 아닌 (또는 NULL이 아닌) 값을 리턴하는 경우, 빨간색 LED를 켜서 오류를 시각적으로 표시 할 수 있습니다. 그렇지 않으면 세 가지 테스트가 모두 성공적으로 완료되면 녹색 LED가 켜질 수 있습니다. 오류가 발생하면 실패한 테스트 루틴은 발생한 문제에 대한 정보를 반환합니다. 이 정보는 하드웨어 설계자 또는 기술자와 문제의 본질에 대해 의사 소통 할 때 유용 할 수 있습니다. 그러나 디버거 또는 에뮬레이터에서 테스트 프로그램을 실행하는 경우에만 표시됩니다.
대부분의 경우 전체 스위트를 다운로드하고 실행하게 됩니다. 그런 다음 메모리 문제가있는 경우에만 디버거를 사용하여 프로그램을 단계별로 실행하고 메모리 장치의 개별 기능 반환 코드와 내용을 검사하여 어떤 테스트가 실패했는지, 왜 실패했는지 확인해야합니다.
불행히도 고급 언어로 메모리 테스트를 작성할 수 있는 것은 아닙니다. 예를 들어 C 언어에서는 스택을 사용해야 합니다. 하지만 스택 자체에는 작업 메모리가 필요합니다. 이것은 하나 이상의 메모리 장치가 있는 시스템에서 합리적 일 수 있습니다. 예를 들어 다른 메모리 장치를 테스트하는 동안 이미 작동 중인 RAM 영역에 스택을 만들 수 있습니다. 이와 같은 상황에서는, 작은 SRAM이 조립 된 상태에서 시험 될 수 있으며 그 후에 스택이 그 곳에 생성 될 수 있습니다. 그런 다음 더 나은 테스트 세트를 사용하여 더 큰 DRAM 블록을 테스트 할 수 있습니다. 테스트 프로그램의 스택 및 데이터 요구에 대해 충분한 RAM을 사용할 수 없다면 이 메모리 테스트 루틴을 어셈블리 언어로 완전히 다시 작성해야합니다. 또 다른 옵션은 인 서킷 에뮬레이터에서 메모리 테스트 프로그램을 실행하는 것입니다. 이 경우 에뮬레이터 자체의 내부 메모리 영역에 스택을 배치하도록 선택할 수 있습니다. 타겟 메모리 맵에서 에뮬레이터의 내부 메모리를 이동하면 타겟에서 각 메모리 장치를 체계적으로 테스트 할 수 있습니다.
메모리 테스트의 필요성은 하드웨어의 안정성과 설계가 아직 입증되지 않은 제품 개발 중에 가장 명백한 부분입니다. 그러나 메모리는 임베디드 시스템에서 가장 중요한 리소스 중 하나이므로 소프트웨어의 최종 릴리스에 메모리 테스트를 포함하는 것이 바람직 할 수 있습니다. 이 경우 메모리 테스트 및 기타 하드웨어 신뢰성 테스트는 시스템의 전원을 켜거나 재설정 할 때마다 실행해야합니다. 함께, 이 초기 테스트 슈트는 일련의 하드웨어 진단을 구성합니다. 하나 이상의 진단이 실패하면 수리 기술자를 불러서 문제를 진단하고 결함이있는 하드웨어를 수리 또는 교체하십시오.
무료 소스 코드
이 메모리 테스트를위한 C 소스 코드는 공개 된 것으로 http://www.barrgroup.com/code/memtest.zip에서 전자 형식으로 구할 수 있습니다. 8051 및 Phillips XA 프로세서에 대한 포트는 http://www.esacademy.com/faq/progs/ram.htm에서 찾을 수 있습니다.




